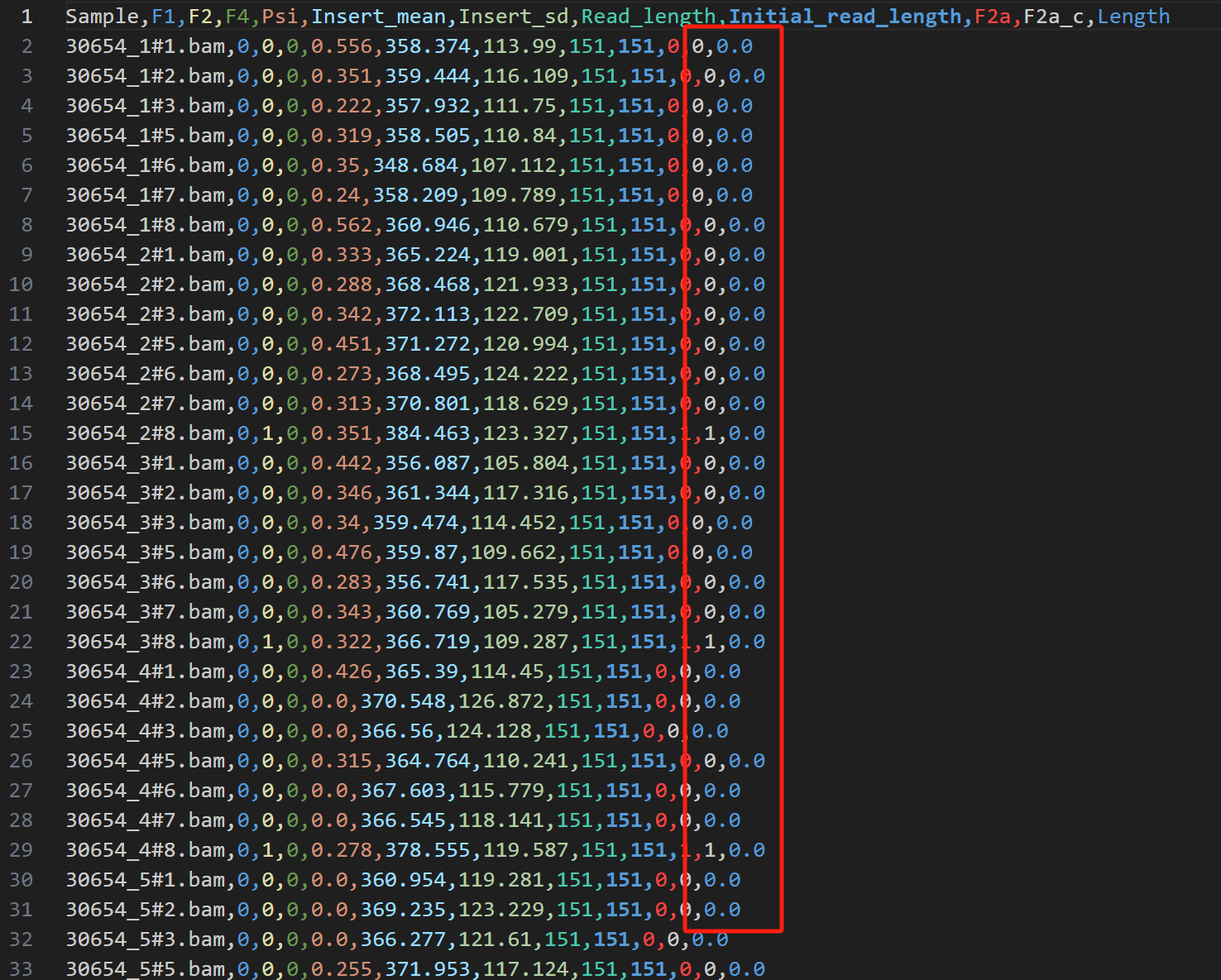
Telomerecat 运行的日志文件提供了关于潜在 Bug 原因的报错信息,如下所示:
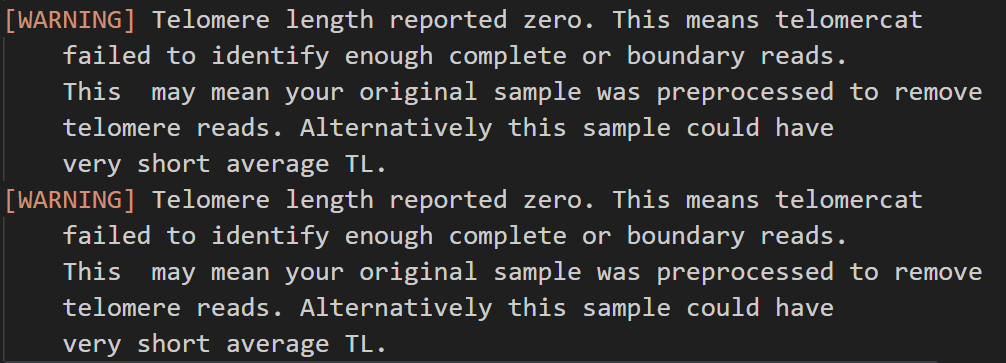
Bug发生原因推断:¶
根据telomerecat的日志文件,和我们实际分析过程中发现的蛛丝马迹,我们推断可能存在三个原因导致telomerecat计算的端粒长度为0。
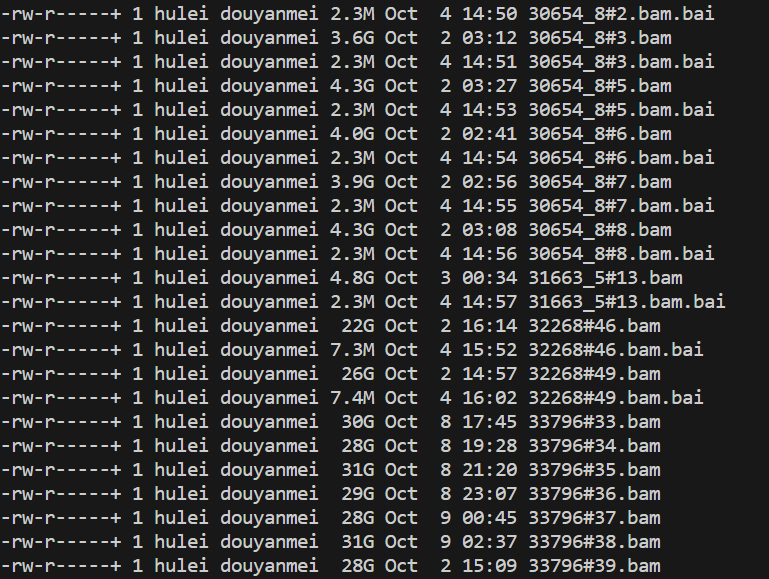
输入的 Bam 文件测序深度较低。¶
过低的测序深度对于 Telomerecat 文件来说可能会导致计算结果的问题,因为它对 Bam 文件的测序深度要求较高。具体来说,在我们的血液数据集中,大约有 95% 的数据估计的端粒长度都为 0,只有 5% 的数据估计具有实际的端粒长度。这 95% 的数据的文件大小大约只有 3-4GB,而具有实际输出结果的 5% Bam 数据文件的大小则约为 30GB,这种较低的测序深度可能导致 Telomerecat 无法捕获低端粒信息。如下图所示:
Bam文件可能经过预处理,删除了端粒相关序列。¶
如果删除了端粒相关序列,那么很自然 Telomerecat 无法正确计算端粒长度。为了确认是否存在这种预处理操作,我们可以通过检查 Bam 文件的头文件来进行验证。
不同的测序手段带来不同的结果。¶
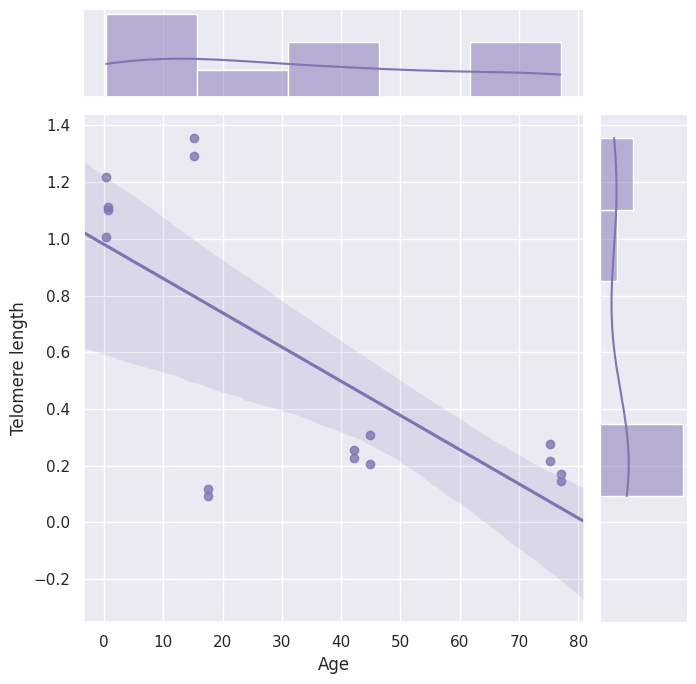
针对大脑神经细胞数据集,我们观察到不同测序手段产生的样本具有明显不同的端粒长度,如下图所示。
通过进一步的调查,我们发现在图的左侧,具有较高端粒长度的样本是通过PTA和Bulk方法进行测序的,而在图的右侧,具有较低端粒长度的样本则是通过MDA方法进行测序的。因此,我们可以合理地推断,不同的测序手段可能会对 Telomerecat 的计算结果产生影响,即MDA测序过程可能忽略了大部分的端粒信号,进而导致 Telomerecat 的估计结果为0。
我们的建议¶
请使用原始的 Bam 文件来进行端粒长度的估计。
请使用测序深度比较高的样本来估计端粒长度。
请确保在比较不同的端粒长度时,所有的样本都采用相同的测序手段。